Pharo语言模型的灵感来自SmallTalk的模型。它简单且统一:一切都是对象,对象之间仅仅通过发送消息来进行通信。实例变量是私有的,方法都是公开的,并且动态查找(延迟绑定)。
在本章中,我们介绍了Pharo对象模型的核心概念。我们对这一章的章节进行了排序,以确保最重要的几个点出现在第一位。我们回顾了self、super等概念,并准确地定义了它们的语义。然后我们讨论了将类表示为对象的结果。这将在第17章.类和元类一章中详细展开。
10.1 核心模型的规则
对象模型基于一组简单的规则,这些规则无一例外地统一并且被系统地应用。规则如下:
规则1:一切都是对象;
规则2:每一个对象都是某个类的实例;
规则3:每一个类都有一个超类;
规则4:一切都通过发送消息发生的;
规则5:方法的查找遵循继承链;
规则6:类也是对象,遵循完全相同的规则。
让我们详细地看一看每一个规则。
10.2 一切都是对象
“万物皆对象”这句格言极具感染力。在与Pharo一起工作了一小段时间后,你就会惊讶于这条规则是如何简化了你所做的一切。例如,整数也是对象,因此您可以给它们发送消息,就像给其他对象发送消息一样。在本章的末尾,我们为好奇的读者添加了关于对象的实现说明。
这里有两个例子。
清单10-1 将+ 4发送给3生成对象7
3 + 4
>>> 7清单10-2 将factorial发送给20生成一个大数字
20 factorial
>>> 2432902008176640000对象7不同于由20 factorial返回的对象。7是SmallInteger的实例,而20 factorial是LargePositiveInteger的实例。但是,因为它们都是多态对象(它们知道如何对同一组消息做响应),所以没有任何代码需要知道这一点,甚至factorial的实现也不需要知道这一点。
回到“一切都是对象”这条规则,也许这条规则最根本的结果就是类也是对象。类不是二等公民:它们实际上是一等公民,你可以象对待其它对象一样给它发送消息,检视它,修改它。
从发送消息的角度来看,像7这样的实例和类没有区别。下面的示例显示,我们可以将消息today发送给Date类,以获取系统的当前日期。
清单10-3 给Date类发送today生成当前日期
Date today printString
>>> '24 July 2021'下面的示例显示,我们可以询问一个类它的实例所拥有的实例变量。请注意,消息allInstVarNames返回的结果中包含了从超类继承而来的实例变量。
重点 类也是对象。我们以相同的方式与类和对象交互,只需要给它们发送消息。
清单10-4 给Date类发送allInstVarNames返回所有的实例变量
Date allInstVarNames
>>> #(#start #duration)10.3 每一个对象都是某个类的实例
每个对象都有一个类,您可以通过向它发送消息class来找出它属于哪个类。
1 class
>>> SmallInteger
20 factorial class
>>> LargePositiveInteger
'hello' class
>>> ByteString
(4@5) class
>>> Point
Object new class
>>> Object类通过实例变量定义其实例的结构,并通过方法定义其实例的行为。每个方法都有一个名字,称之为方法的选择器,在类中是唯一的。
由于类本身也是对象,并且每个对象都是类的实例,因此类也必须是某个类的实例。类所属的类称为元类。无论何时当你创建了一个类,系统都会自动为您创建一个元类。元类定义了它的实例(你所创建的类)的结构和行为。在99%的时间中您都不需要考虑元类,可以愉快地忽略它们。我们将在第17章.类和元类一章中更详细地了解元类。
10.4 实例的结构和行为
现在,我们将简要介绍如何指定实例的结构和行为。
实例变量
在当前类的所有实例方法,及其子类的方法中,都可以通过名字直接访问实例变量。这意味着Pharo的实例变量类似于C++和Java中的protected变量。然而,我们更愿意说它们是私有的,因为在Pharo中,从子类中直接访问实例变量被认为是不好的风格。 基于实例的封装
Pharo中的实例变量是实例本身的私有变量。这与Java和C++不同,Java和C++允许属于同一个类的其他实例访问实例变量(也称为字段或成员变量)。我们说Java和C++中对象的封装边界是类,而在Pharo中是实例。
在Pharo中,同一个类的两个实例不能相互访问对方的实例变量,除非该类定义了访问器方法。Pharo没有提供直接访问其他对象的实例变量的语法。实际上,有一种被称为“反射”的机制提供了一种向另一个对象请求其实例变量值的方法。反射是元编程的根源,元编程用于编写对象检查器等工具。
实例封装示例
Point类的方法distanceTo:计算接收者和另一个坐标点之间的距离。在方法体中可以直接访问接收者的实例变量x和y。但是,必须通过向另一个点发送消息x和y来访问它的实例变量。
清单10-5 两点之间的距离
Point >> distanceTo: aPoint
"Answer the distance between aPoint and the receiver."
| dx dy |
dx := aPoint x - x.
dy := aPoint y - y.
^ ((dx * dy) + (dy * dy)) sqrt
1@1 distanceTo: 4@5
>>> 5.0选择基于实例的封装而非基于类的封装的关键原因是,它允许同一个抽象的不同实现共存。例如,方法distanceTo:不需要知道或关心参数aPoint是否是与接收者相同的类的实例。
参数对象可以表示一个坐标,或者表示为数据库中的记录,或者表示为分布式系统中另一台计算机上的记录。只要它能够响应消息x和y,方法distanceTo:(如上所示)的代码仍然有效。(鸭子类型?)
方法
所有方法都是公共的和虚拟的(即,动态查找)。在Pharo中没有静态方法。方法可以访问对象的所有实例变量。一些开发人员倾向于仅通过访问器访问实例变量。这种做法有一定的价值,但它也会扰乱类的接口,更糟糕的是,它会将私有状态暴露给外界。
为了简化类的浏览,方法被分组到不同的协议中,协议名表达了其意图。从语言的层面看,协议并没有实际的语义。它们只是存储方法的文件夹。根据约定,已经建立了一些常见的协议名,例如,accessing针对所有访问器方法,initialization用于为对象建立一致的初始状态。
private协议有时候用于对非API方法进行分组。没有什么可以阻止您调用这些“私有”方法。然而,这意味着在未来开发人员可能会修改或移除这些私有方法。(那么依赖于这些隐藏API的代码将无法正常工作)
10.5 每个类都有一个超类
Pharo中的每个类都从一个超类继承其行为和对其结构的描述。这意味着Pharo只提供单一继承。
这里有一些例子,展示了我们如何在层次结构中浏览。
SmallInteger superclass
>>> Integer
Integer superclass
>>> Number
Number superclass
>>> Magnitude
Magnitude superclass
>>> Object
Object superclass
>>> ProtoObject
ProtoObject superclass
>>> nil传统上,类结构的根是Object类,因为一切都是对象。大多数的类继承自Object,它定义了许多附加消息,几乎所有对象都能理解和响应这些消息。
在Pharo中,继承树的根实际上是ProtoObject类,但是您通常不会注意到这个类。ProtoObject类封装了所有对象都必须具备的最小消息集,并且ProtoObject被设计为引发尽可能多的错误(以支持代理定义)。除非您有很充分的理由,否则在创建应用程序时,通常应该通过继承Object类或其子类来创建你自己的类。
定义新的类通常是通过向已有的类发送消息subclass:instanceVariableNames:...来创建的,如10-6中所示。还有一些别的方法可以创建类。要了解还有哪些方法可以创建新的类,请看一下Class及其subclass creation协议。
清单10-6 Point类的定义
Object subclass: #Point
instanceVariableNames: 'x y'
classVariableNames: ''
package: 'Kernel-BasicObjects'10.6 一切都是通过发送消息来实现的
这条规则抓住了Pharo编程的精髓。
在过程性编程中(以及在某些面向对象语言的静态特性中,例如Java),在调用过程时具体执行哪个方法是由调用者决定的。调用者按照名称选择要静态执行的过程。在这种情况下,不涉及方法的查找或动态绑定。
在Pharo中,当我们发送消息时,调用者并不能决定具体会执行哪个方法。相反,我们只是通过给对象发送消息来告诉它做某件事。消息只不过是一个名字和一个参数列表。然后,接收者通过选择自己的方法来完成所要求的操作,从而决定如何做出响应。由于不同的对象可能有不同的方法来响应相同的消息,因此必须在接收到消息时动态地选择方法。
因此,我们可以将相同的消息发送给不同的对象,每一个对象都可能有它自己响应消息的方法。
在前面的示例中,我们并不决定SmallInteger 3或Point (1@2)应该如何响应消息+ 4。我们让对象自己决定:每个对象都有自己的+方法,并对+ 4做出相应的响应。
清单10-7 将消息+和参数4发送给整数3
3 + 4
>>> 7清单10-8 将消息+和参数4发送给坐标点(1@2)
(1@2) + 4
>>> 5@6术语
在Pharo中,我们通常不会说“调用方法”。相反,我们称为“发送消息”。这只是一个术语,但是它很重要。这意味着选择所要执行的方法并不是客户端的责任,而是消息接收者的责任。
例外
在Pharo中,几乎所有的事情都是通过发送消息触发的。下面这些除外:
变量声明 不是消息发送。事实上,变量声明甚至不是可执行的。声明变量的结果只是为对象引用分配内存空间。
变量访问 只是对变量值的访问。
赋值 不是消息发送。对变量的赋值会导致该变量名重新绑定到其作用域内某个表达式的结果上。
return(
^)不是消息发送,return只是将计算结果返回给发送者。Pragmas 不是消息发送,它们是方法注释。
除了这几个例外,几乎所有其他的事情都是通过发送消息来实现的。
关于面向对象编程
Pharo的消息发送模型所导致的后果之一,是它鼓励一种风格,即对象的方法往往非常小,将尽量多的任务委托给其他对象,而不是去实现一庞大的,承担了过多责任的过程性方法。
约瑟夫·佩林简明扼要地表达了这一原则:
Note 凡是可以推卸给别人的事情你都不要亲自去做。
许多面向对象的语言都提供了对对象的静态和动态操作。在Pharo中,只有动态的消息发送。例如,我们不提供静态的类方法,而是简单地将消息发送给类(类也是对象)。
特别是,由于Pharo中没有public字段,更新另一个对象的实例变量的唯一方法是给它发送消息,要求它更新自己的字段。当然,为对象的所有实例变量都提供setter和getter方法并不是好的面向对象风格,因为客户端可以直接访问对象的内部状态。
约瑟夫·佩林也很好地阐述了这一点:
Note 不要让别人摆弄你的数据。
10.7 发送消息:分两步走的过程
当对象收到消息时,具体会发生什么情况?
这个过程分为两步:方法查找和方法执行。
方法查找 首先,查找与消息同名的方法。
方法执行 其次,将找到的方法应用于带有消息参数的接收者:当找到方法时,参数绑定到方法的参数,并由虚拟机执行该方法。
查找的过程非常简单:
接收者的类查找用于处理消息的方法。
如果该类没有定义该方法,它会请求它的超类,依此类推,沿着继承链一直向上查找。
事情本质上就是如此简单。然而,还有几个问题需要仔细地回答:
如果方法没有显式地返回值,会发生什么情况?
当类重新实现了超类的方法时会发生什么?
发送给
self和发送给super有什么不同?如果消息没有找到会发生什么?
清单10-9 本地实现的方法
EllipseMorph >> defaultColor
"Answer the default color/fill style for the receiver"
^ Color yellow清单10-10 继承的方法
Morph >> openInWorld
"Add this morph to the world"
self openInWorld: self currentWorld我们在这里介绍的方法查找规则只是概念性的;虚拟机的实现者使用了各种技巧和优化来加速方法的查找。
首先让我们来看看基本的查找策略,然后再考虑这些进一步的问题。
10.8 方法的查找遵循继承链
假设我们创建了一个EllipseMorph实例。
anEllipse := EllipseMorph new.如果我们现在向该对象发送消息defaultColor,我们将得到结果Color yellow。
anEllipse defaultColor
>>> Color yellowEllipseMorph类实现了defaultColor,因此它可以立即找到合适的方法。
相反,如果我们向anEllipse发送消息openInWorld,则不会立即找到该方法,因为EllipseMorph类没有实现openInWorld。因此,在其超类BorderedMorph中继续搜索,直到在Morph类中找到一个openInWorld方法(参见图10-11)。
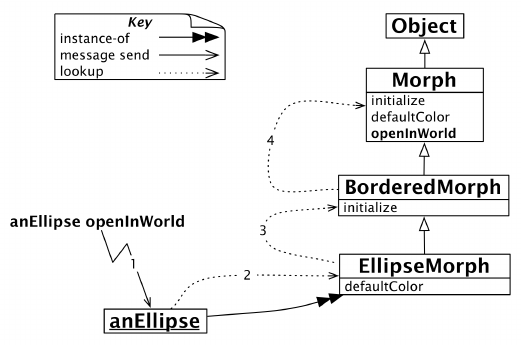
图10-11 方法查找遵循继承链
10.9 方法的执行
我们提到,消息的发送是一个分两步进行的过程:
查找 首先,查找与消息同名的方法。
执行方法 其次,将找到的方法应用于带有消息参数的接收者:当找到方法时,参数绑定到方法的参数,并由虚拟机执行该方法。
现在我们解释第二点:方法执行。
当查找返回一个方法时,消息的接收者被绑定到self,消息的参数被绑定到方法参数。然后,系统执行方法体。无论在哪里找到应该执行的方法,都是如此。假设我们发送消息EllipseMorph new closestPointTo: 100@100,并且该方法的定义如清单10-12所示。
清单10-12
EllipseMorph >> closestPointTo: aPoint
^ self intersectionWithLineSegmentFromCenterTo: aPoint
变量self将会指向我们创建的新椭圆,aPoint将指向坐标点100@100。
现在,接下来的过程完全相同,即使该方法是在超类中找到的也是如此。当我们发送消息EllipseMorph new openInWorld时。在Morph类中可以找到方法openInWorld。尽管如此,变量self仍被绑定到新创建的椭圆。这就是为什么我们说self总是表示消息的接收者,与找到该方法的类无关。
这就是为什么在消息发送过程中有两个不同的步骤:在消息接收者的类层次结构中查找方法以及在消息接收者本身上执行方法。
10.10 消息未被理解
如果找不到我们需要的方法,会发生什么?
假设我们将消息foo发送到椭圆。首先,正常的方法查找将遍历继承链,直到查找到Object(或者更确切地说是ProtoObject)。当找不到该方法时,虚拟机将让对象发送self doesNotUnderstand: #foo(参见图10-13)。
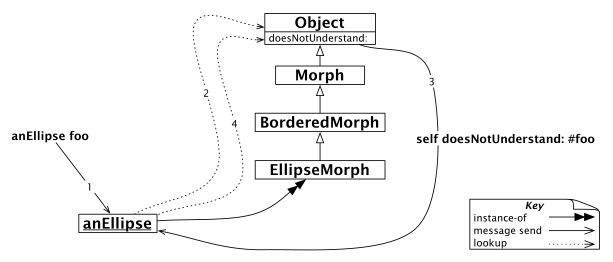
图10-13 消息`foo`无法被理解
现在,这是一个非常普通的动态消息发送,所以查找再次从EllipseMorph类开始,但是这一次要搜索的方法是doesNotUnderstand:。事实证明,Object实现了doesNotUnderstand:。该方法将创建一个新的MessageNotUnderstand对象,该对象能够在当前的执行上下文中启动调试器。
为什么我们要通过这条曲折的道路来处理如此明显的错误呢?
这为开发人员提供了一种拦截此类错误并采取替代操作的简单方法。可以很容易地覆盖掉Object的任何子类中的方法Object>>doNotUnderstand:,以提供一种不同的错误处理方式。
事实上,这是实现消息从一个对象自动委派到另一个对象的一种简单方法。委托对象可以简单地将它不理解的所有消息委托给负责处理它们的另一个对象,或者引发错误本身!
10.11 关于返回self
请注意,EllipseMorph类的方法defaultColor显式返回Color yellow,而Morph的openInWorld方法似乎没有返回任何东西。
实际上,一个方法总是用一个值(当然是一个对象)来回复消息。具体答案可以由方法中的^语法来定义,但是如果执行到达方法的末尾而没有执行^,则方法仍然会回答一个值-它会返回接收消息的对象本身。我们通常说该方法返回self,因为在Pharo中,伪变量self表示消息的接收者,很像Java中的关键字this。默认情况下,其他语言(如Ruby)返回方法中最后一条语句的值。同样,在Pharo中情况并非如此,相反,您可以假设没有显式返回值的方法都是以^ self结尾的。
重点
self始终表示消息的接收者。
这表明openInWorld与清单10-14中定义的openInWorldReturnSelf是等同的。
清单10-14
Morph >> openInWorldReturnSelf
"Add this morph to the world."
self openInWorld: self currentWorld
^ self为什么明确地书写^ self不是一个好主意呢?
当你明确地返回一些东西时,你是在传达你正在将一些感兴趣的东西返还给发送者。当您显式地返回self时,表明您希望返回值对发送者是有用的。这里的情况并非如此,所以最好不要显式地返回self。我们只在特殊情况下返回self,以强调接收者已返回。
这是Pharo中一个常见的习惯性用法,Kent Beck将其称为有趣的返回值:“只有当您打算让发送者使用某个值时才返回值。”
重点 默认情况下(如果没有以不同方式指定),方法会返回消息接收者本身。
10.12 覆盖和扩展
如果我们再次查看图10-11中的EllipseMorph类的层次结构,我们会看到Morph类和EllipseMorph都实现了defaultColor。事实上,如果我们打开一个新的Morph(Morph new openInWorld),我们会看到一个蓝色的Morph,而椭圆在默认情况下将是黄色的。
我们说EllipseMorph覆盖了它从Morph继承的defaultColor方法。站在anEllipse的角度看,继承的方法并不存在。
有时我们并不想完全重写继承的方法,而是用一些新的功能来扩展它们,也就是说,除了在子类中定义的新功能之外,我们还希望能够调用被重写的方法。在Pharo中,就像在许多支持单继承的面向对象语言中一样,可以通过发送super来实现。
该机制的一个常见应用是在initialize方法中。每当初始化类的新实例时,也要初始化所有继承的实例变量。然而,具体的操作已经存在于继承链中每一个超类的initialize方法中了。子类没有必要去初始化继承的实例变量!
因此,在执行如清单10-15所示的任何进一步初始化之前,只要实现一个initialize方法来发送super initialize,这就是一个很好的实践。
清单10-15
BorderedMorph >> initialize
"Initialize the state of the receiver"
super initialize.
self borderInitialize
我们需要super发送来编写继承的行为,否则这些行为将被覆盖掉。
重点 以
super initialize作为initialize方法的开头是一个良好的做法。
10.13 self和super
self表示消息的接收者,方法的查找从接收者的类开始。现在,什么是super呢?super并不是超类!这是一个常见而自然的错误。认为查找是从接收者的类的超类开始的想法也是错误的。
重点
self表示消息的接收者,方法查找从接收者的类中开始。
发送给self和发送给super有什么不同?
和self一样,super代表消息的接收者。唯一变化的是方法查找。super不是从接收者的类开始查找,而是从发生super消息发送的方法的类的超类开始。
重点
super表示消息的接收者,方法查找从发生super发送的方法的类的超类中开始。
我们将在下面的示例中确切地看到这是如何工作的。假设我们定义了下面三个方法:
首先,在清单10-16中,我们在Morph类中定义了fullPrintOn:方法,它只是将类名添加到流中,后面跟着字符串' new'。我们的想法是,可以将产生的字符串作为代码去执行,并返回一个与接收者类似的实例。
清单10-16
Morph >> fullPrintOn: aStream
aStream nextPutAll: self class name, ' new'
其次,下面定义的constructorString方法(参见清单10-17)用到了fullPrintOn:消息.
清单10-17
Morph >> constructorString
^ String streamContents: [ :s | self fullPrintOn: s ].
最后,在EllipseMorph的超类BorderedMorph上定义了方法fullPrintOn:。这个新方法扩展了超类的行为:它调用超类的行为并添加了额外的行为(参见清单10-18)。
清单10-18
BorderedMorph >> fullPrintOn: aStream
aStream nextPutAll: '('.
super fullPrintOn: aStream.
aStream
nextPutAll: ') setBorderWidth: ';
print: borderWidth;
nextPutAll: ' borderColor: ', (self colorString: borderColor)
考虑一下发送给EllipseMorph实例的constructorString消息:
EllipseMorph new constructorString
>>> '(EllipseMorph new) setBorderWidth: 1 borderColor: Color black'这个结果到底是如何通过组合self和super获得的?首先,anEllipse constructorString会导致在Morph类中找到constructorString方法,如图10-19所示。
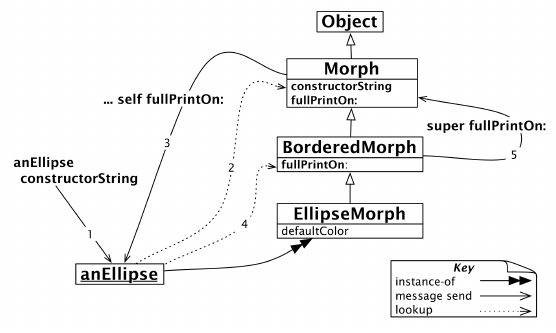
Morph的constructorString方法执行self的fullPrintOn:。从EllipseMorph类开始查找fullPrintOn:方法,在BorderedMorph中找到fullPrintOn:方法(参见图10-19)。需要注意的是,发送self导致方法查找在接收者的类中再次开始,也就是在anEllipse的类中。
此时,BorderedMorph的方法fullPrintOn:执行了一个super发送,以扩展它从其超类继承的fullPrintOn:行为。
因为这是一个super发送,所以现在在super发送发生的类的超类中开始查找,即在Morph中。然后,我们立即找到并执行Morph类的方法fullPrintOn:。
10.14 回顾一下
self发送是动态的,因为通过查看包含它的方法,我们无法预测将会执行哪个方法。实际上,子类的实例可能会接收到包含self表达式的消息,并重新定义了该子类中的方法。在这里,EllipseMorph可以重新定义fullPrintOn:方法,并且该方法将由constructorString方法执行。请注意,仅仅查看constructorString方法,我们无法预测在执行constructorString方法时将会执行哪一个fullPrintOn:方法(EllipseMorph、BorderedMorph或Morph中的其中之一),因为它依赖于接收者的constructorString消息。
重点
self发送触发从接收者的类开始的方法查找。self发送是动态的,因为通过查看包含它的方法,我们无法预测将会执行哪个方法。
请注意,super查找不是从接收者的超类开始的。这将导致查找从BorderedMorph开始,陷入无限循环!
如果仔细思考super发送和图10-19,你会意识到super绑定是静态的:最重要的是文本super所出现的类。相比之下,self的含义是动态的:它始终代表当前执行消息的接收者。这意味着发送给self的所有消息都是从接收者的类开始查找的。
重点
super发送触发从执行super发送的方法的类的超类开始的方法查找。我们说super发送是静态的,因为只要看看方法,我们就知道应该从哪里开始查找的类(包含该方法的类上方的类)。
10.15 实例侧和类侧
因为类也是对象,所以它们有自己的实例变量和方法。我们将这些类实例变量和方法称为类实例变量和类方法,但它们实际上与普通实例变量和方法没有什么不同:它们只是对不同的对象(本例中为类)进行操作。
实例变量描述实例的状态,方法描述实例的行为。
类似地,类实例变量只是由元类(其实例是类的类)定义的实例变量:
类实例变量描述类的状态。描述给定类的超类的超类实例变量就是一个例子。
类方法只是元类定义的方法,将在类上执行。
Date类的now消息是在(元)类Date class中定义的。该方法以Date类作为接收者执行。
类及其元类是两个独立的类,尽管前者是后者的一个实例。但是,作为程序员,在很大程度上这与您无关:您关心的是定义对象的行为和创建它们的类。
由于这个原因,浏览器帮助你浏览类和元类,就好像它们是一个有两个“面”的东西:实例侧和类侧,如图10-20所示。
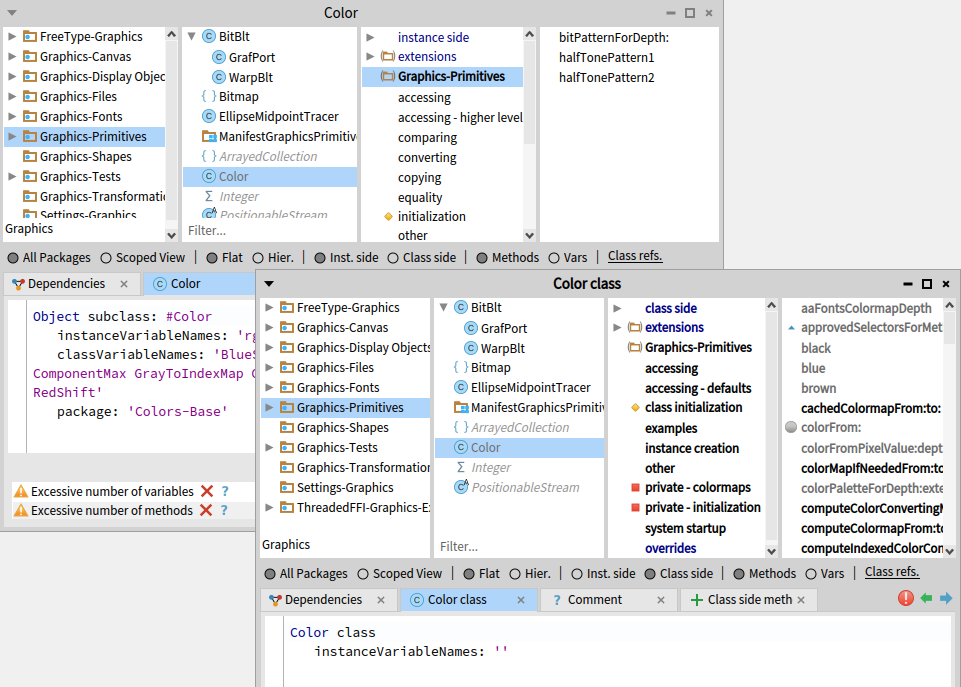
默认情况下,当您在浏览器中选择一个类时,您正在浏览实例侧,即当消息被发送到
Color实例时执行的方法。单击'Class Side'按钮将切换到类侧:当消息被发送给
Color类本身时将会执行的方法。
例如,Color blue将消息blue发送给Color类。因此,您会发现该方法是在Color的类侧定义的,而不是在实例侧定义的。
元类创建
您可以通过填充实例侧所建议的模板来定义一个类。当您编译此模板时,系统不仅会创建您定义的类,还会自动创建相对应的元类(然后您可以通过单击'Class Side'按钮来编辑它)。元类创建模板中对您直接编辑有意义的唯一部分是元类的instanceVariableNames:列表。
一旦创建了一个类,浏览它的实例侧就可以编辑和浏览该类(及其子类)的实例所拥有的方法。
10.16 类方法
类方法可能非常有用,您可以浏览Color class以找到一些很好的示例:您将会看到在类上面定义了两种方法:实例创建方法,如Color class类中的类方法blue,以及执行实用程序函数的方法,如Color class>>wheel:。这是类方法的典型用途,尽管您偶尔会发现类方法还有其他的使用方式。
将实用程序方法放在类的一侧是很方便的,因为它们不需要首先创建额外的对象即可执行。事实上,其中许多都会包含一条旨在使执行它们变得容易的注释。
浏览Color class>>wheel:方法,在注释"(Color wheel: 12) inspect"的开始处双击,然后按CMD-d。您将会看到执行此方法的效果。
对于那些熟悉Java和C++的人来说,类方法可能看起来类似于静态方法。然而,Pharo对象模型(其中的类也只是普通对象)的一致性意味着它们有一些不同:Java静态方法实际上只是静态解析的过程,而Pharo类方法是动态调度的方法。这意味着继承、覆盖和发送super适用于Pharo中的类方法,而不适用于Java中的静态方法。
清单10-21
Color blue
>>> Color blue
"Color实例是自求值的"清单10-22
Color blue red
>>> 0.0清单10-23
Color blue blue
>>> 1.010.17 类的实例变量
对于普通的实例变量,类的所有实例都有相同的变量集(尽管每个实例都有自己私有的变量值),其子类的实例也继承了这些变量。
类实例变量的情况与此完全相同:一个类是另一个类的对象实例。因此,类的实例变量是在这样的元类上定义的,并且每个类都有自己的类实例变量的私有值。
实例变量也适用。类实例变量是继承的:子类将继承这些类实例变量,但子类将拥有这些变量的自己的私有副本。正如对象不共享实例变量一样,类及其子类也不共享类的实例变量。
例如,您可以使用一个名为count的类实例变量来跟踪您为给定的类创建了多少个实例。但是,任何子类都将有自己的计数变量,因此子类的实例将被单独计数。以下部分提供了一个示例。
清单10-24
Object subclass: #Dog
instanceVariableNames: ''
classVariableNames: ''
package: 'Example'
清单10-25
Dog class
instanceVariableNames: 'count'
10.18 示例:类的实例变量和子类
假设我们定义了Dog类及其子类Hyena。假设我们向Dog类添加了一个count类实例变量(即,我们在元类Dog class上定义了它)。Hyena自然会从Dog继承类实例变量count。
现在,假设我们为Dog定义类方法,以便将其计数初始化为0,并在创建新实例时递增计数:
清单10-26
Dog subclass #Hyena
instanceVariableNames: ''
classVariableNames: ''
package: 'Example'
清单10-27
Dog class >> initialize
count := 0.
清单10-28
Dog class >> new
count := count + 1.
^ super new
现在,当我们创建新的Dog时,Dog类的count值会递增,Hyena类的count值也会递增(但鬣狗是单独计数的)。
关于类的初始化
当您实例化一个对象(如Dog new)时,在new消息发送过程中会自动调用initialize(您可以通过浏览类行为中的new方法亲自查看)。但是对于类,简单地定义它们并不会自动调用初始化,因为系统不清楚类是否完全工作。所以我们必须在这里显式地调用initialize。
默认情况下,只有在加载类时才会自动执行类initialize方法。另请参阅下面关于延迟初始化的讨论。
Hyena count
>>> 0
| aDog |
aDog := Dog new.
Dog count
>>> 1 "已经递增"
Hyena count
>>> 0 "没有变化"清单10-29
Dog class >> count
^ count
Dog initialize.
Hyena initialize.
Dog count
>>> 010.19 回顾一下
类实例变量是类的私有变量,其方式与实例变量私有的方式完全相同。由于类及其实例是不同的对象,因此会产生以下后果:
类无权访问其自身实例的实例变量。因此,
Color类无权访问从它实例化的aColorRed对象的变量。换句话说,仅仅因为一个类被用来创建一个实例(使用new或其它辅助实例创建方法,如Color red),它不会为该类提供对该实例的变量的任何特殊的直接访问。相反,类必须像任何其他对象一样通过访问器方法(公共接口)。反之亦然:类的实例无权访问其类的类实例变量。在上面的示例中,
aDog(单个实例)不能直接访问Dog类的count变量(同样,通过访问器方法除外)。
重点 类无权访问其自身实例的实例变量。类的实例无权访问其类的类实例变量。
因此,实例的初始化方法必须始终在实例侧定义,在类侧无权访问实例变量,因此无法对其进行初始化!类所能做的就是使用访问器向新创建的实例发送初始化消息。
Java没有等同于类实例变量的东西。Java和C++静态变量更像是Pharo的类变量(在第10.23节中讨论),因为在这两种语言中,所有子类及其所有实例共享相同的静态变量。
10.20 示例:定义一个Singleton
Singleton是最容易被误解的设计模式。当被错误地应用时,它倾向于促进单一全局访问的程序风格。但是,Singleton模式提供了一个使用类实例变量和类方法的典型示例。
假设我们想要实现一个WebServer类,并使用Singleton模式来确保它只有一个实例。
清单10-31
WebServer class allInstVarNames
>>> "#(#superclass #methodDict #format #layout #organization
#subclasses #name #classPool #sharedPools #environment #category
#uniqueInstance)"
我们将WebServer类定义如下。
Object subclass: #WebServer
instanceVariableNames: 'sessions'
classVariableNames: ''
package: 'Web'
然后,单击'Class Side'按钮,我们来添加一个(类)实例变量uniqueInstance。
WebServer class
instanceVariableNames: 'uniqueInstance'
因此,WebServer class类将有一个新的实例变量(除了它从Behavior继承的变量,如superclass和methodDict)。这意味着这个额外的实例变量的值将描述WebServer class的实例,即WebServer类。
Point class allInstVarNames
>>> "#(#superclass #methodDict #format #layout #organization
#subclasses #name #classPool #sharedPools #environment #category)"[注]原书中的这段代码估计放错地方了,上下文根本就没有在讲 Point 类。
我们现在可以定义一个名为uniqueInstance的类方法,如下所示。此方法首先检查uniqueInstance是否已初始化。如果没有,该方法将创建一个实例,并将其赋给类实例变量uniqueInstance。最后,返回uniqueInstance的值。因为uniqueInstance是一个类实例变量,所以此方法可以直接访问它。
清单10-32
WebServer class >> uniqueInstance
uniqueInstance ifNil: [ uniqueInstance := self new ].
^ uniqueInstance[注]这段代码在原书中位于前面的位置,权衡后,我认为放在这里更合适。
第一次执行WebServer uniqueInstance时,将创建一个WebServer类的实例并将其赋值给uniqueInstance变量。下一次,将返回先前创建的实例,而不是创建新实例。(这种模式在访问器方法中检查变量是否为nil,如果为nil则初始化它的值,称为惰性初始化)。
请注意,上面代码中的实例创建代码。脚本10-32被写为self new,而不是WebServer new。这有什么不同?由于uniqueInstance方法是在WebServer class中定义的,因此您可能认为没有区别。事实上,除非有人创建WebServer的子类,否则它们确实是相同的。但假设ReliableWebServer是WebServer的子类,并继承了uniqueInstance方法。我们显然希望ReliableWebServer uniqueInstance返回ReliableWebServer的实例。
使用self可以确保这种情况的发生,因为self将绑定到各自的接收者,这里分别是WebServer类和ReliableWebServer类。另外请注意,WebServer和ReliableWebServer将分别为其uniqueInstance变量指定不同的值。
10.21 延迟初始化注记
对象实例的初始值的设置通常属于initialize方法。从可读性的角度来看,只将初始化调用放在initialize中是有帮助的-您不需要遍历所有的访问器方法来查看初始值是什么。尽管在各自的存取器方法中初始化实例变量可能很诱人(使用ifNil:检查),但是,除非有充分的理由,否则不要这样干。
不要过度使用延迟初始化模式。
例如,在上面的uniqueInstance方法中,我们使用了延迟初始化,因为用户通常不会期望调用WebServer initialize。相反,他们希望类“准备好”返回新的唯一实例。正因为如此,延迟初始化还是有意义的。同样,如果某个变量的初始化成本很高(例如,打开数据库连接或网络套接字),您有时会选择将初始化延迟到实际需要时再进行。
10.22 共享变量
现在我们来看看Pharo的一个方面,这是我们的五条规则不太容易涵盖的:共享变量。
Pharo提供了三种共享变量:
全局共享变量;
类变量:实例和类之间共享的变量。(不要与前面讨论的类实例变量混淆);
池变量:在一组类之间共享的变量。
所有这些共享变量的名称都以大写字母开头,以提醒我们它们是在多个对象之间共享的。
全局变量
在Pharo中,所有全局变量都存储在一个名为Smalltalk globals的命名空间中,该命名空间作为SystemDictionary类的一个实例实现。全局变量在任何地方都可以访问。每个类都由一个全局变量命名。此外,一些全局变量用于命名特殊或常用的对象。
变量Processor命名了一个ProcessScheduler实例,它是Pharo的主进程调度器。
Processor class
>>> ProcessorScheduler其它有用的全局变量
Smalltalk是SmalltalkImage的实例。它包含许多系统管理功能。特别是,它包含对主命名空间Smalltalk globals的引用。此命名空间包括Smalltalk本身,因为它是一个全局变量。此命名空间的关键是用Pharo代码命名全局对象的符号。所以,举个例子:
Smalltalk globals at: #Boolean
>>> BooleanSmalltalk本身是一个全局变量:
Smalltalk globals at #Smalltalk
>>> Smalltalk
(Smalltalk globals at: #Smalltalk) == Smalltalk
>>> trueWorld是表示屏幕的PasteUpMorph的实例。World bounds回答与整个屏幕空间对应的矩形;屏幕上的所有Morph都是World的子Morph。
Undeclared是另外一个字典,它包含所有未声明的变量。如果编写引用了未声明变量的方法,浏览器通常会提示您将其声明为全局变量或类的实例变量。但是,如果稍后删除该声明,则代码将引用一个未声明的变量。检视Undeclared有时有助于解释奇怪的行为!
在你的代码中使用globals
建议的做法是严格限制全局变量的使用。通常,最好使用类实例变量或类变量,并提供访问它们的类方法。事实上,假设今天要从头实现Pharo的话,大多数不是类的全局变量将被单例或其他变量取代。
定义全局变量的通常方法是对一个未声明的大写标识符执行 Do it。然后解析器会提示你声明该全局变量。如果你想以编程方式定义全局变量,只需执行 Smalltalk globals at: #AGlobalName put: nil。要删除它,执行 Smalltalk globals removeKey: #AGlobalName。
10.23 类变量:共享变量
有时,我们需要在类的所有实例和类本身之间共享一些数据。这可以通过使用类变量来实现。术语类变量表示变量的生存期与类的生存期相同。然而,这个术语没有传达的是,这些变量在类的所有实例以及类本身之间共享,如图10-33所示。事实上,更好的名称应该是共享变量,因为这更清楚地表达了它们的作用,并提示了使用它们的危险,特别是如果它们被修改的话。
在图10-33中,我们看到rgb和cachedDepth是Color的实例变量,因此只有Color的实例可以访问。我们还可以看到,superclass、subclass、methodDict等都是类实例变量,即实例变量只能由Color类访问。
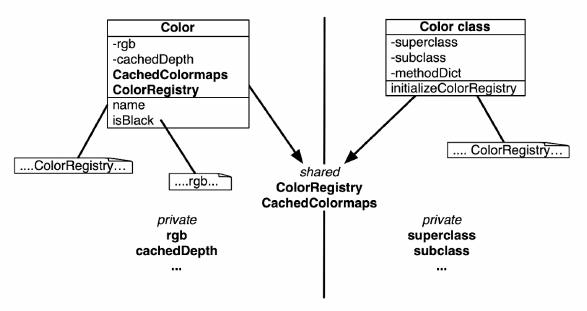
但是我们也可以看到一些新的东西:ColorRegistry和CachedColormap是为Color定义的类变量。这些变量的大写给了我们一个提示,它们是共享的。事实上,不仅所有Color的实例可以访问这些共享变量,Color类本身以及它的子类也可以访问。实例方法和类方法都可以访问这些共享变量。
类变量在类定义模板中声明。例如,Color类定义了大量的类变量来加速颜色创建;它的定义如脚本10-34所示。
清单10-34 Color和它的类变量
Object subclass: #Color
instanceVariableNames: 'rgb cachedDepth cachedBitPattern alpha'
classVariableNames: 'BlueShift CachedColormaps ColorRegistry
ComponentMask ComponentMax GrayToIndexMap GreenShift
HalfComponentMask IndexedColors MaskingMap RedShift'
package: 'Colors-Base'
清单10-35 使用延迟初始化
ColorNames ifNil: [ self initializeNames ].
^ ColorNames
类变量ColorRegistry是由名称引用的、包含常用颜色的IdentityDictionary的一个实例。此词典由Color的所有实例以及类本身共享。它可以从所有实例和类方法进行访问。
类初始化
类变量的存在提出了一个问题:我们如何初始化它们?
一种解决方案是延迟初始化(在本章前面讨论过)。可以通过引入访问器方法来完成,该方法在执行时,如果变量尚未初始化,则对其进行初始化。这意味着我们必须始终使用访问器,而不是直接使用类变量。这进一步增加了访问器发送和初始化测试的成本。
另一种解决方案是覆盖类方法initialize(我们以前在Dog示例中看到过这种情况)。
如果采用此解决方案,则需要记住在定义该方法后调用该方法(通过对Color initialize求值)。尽管类侧initialize方法在代码加载到内存中(例如,从Monticello存储库中)时会自动执行,但当它们第一次在浏览器中输入并进行编译时,或者当它们被编辑和重新编译时,它们不会自动执行。
清单10-36 初始化Color类
Color class >> initialize
...
self initializeColorRegistry.
...
10.24 池变量
池变量是在几个类之间共享的变量,这些变量可能与继承不相关。池变量应该定义为专用类的类变量(SharedPool的子类,如下所示)。我们的建议是避免使用它们;你只有在罕见和特定的情况下才需要它们。因此,我们的目标是对池变量进行足够的解释,以便您在阅读代码时能够理解它们。
访问池变量的类必须在其类定义中提到池。例如,Text类指示它正在使用池TextConstants,该池包含所有文本常量,如CR和LF。TextConstants定义了绑定到Character cr的变量CR,即回车符。
清单10-37 Text类中的池字典
ArrayedCollection subclass: #Text
instanceVariableNames: 'string runs'
classVariableNames: ''
poolDictionaries: 'TextConstants'
package: 'Collections-Text'
这允许Text类的方法直接访问方法体中的共享池的变量。例如,我们可以编写以下方法。我们看到,即使Text没有定义变量CR,因为它声明它使用共享池TextConstants,所以它可以直接访问它。
清单10-38 Text>>testCR
Text >> testCR
^ CR == Character cr
下面是TextConstants的创建方式。TextConstants是SharedPool的一个特殊类子类,它保存类变量。
SharedPool subclass: #TextConstants
instanceVariableNames: ''
classVariableNames: 'BS BS2 Basal Bold CR Centered Clear CrossedX
CtrlA CtrlB CtrlC
CtrlD CtrlDigits CtrlE CtrlF CtrlG CtrlH
CtrlI CtrlJ CtrlK CtrlL CtrlM CtrlN CtrlO CtrlOpenBrackets CtrlP
CtrlQ CtrlR CtrlS CtrlT
CtrlU CtrlV CtrlW CtrlX CtrlY CtrlZ Ctrla Ctrlb Ctrlc Ctrld Ctrle
Ctrlf Ctrlg Ctrlh Ctrli
Ctrlj Ctrlk Ctrll Ctrlm Ctrln Ctrlo Ctrlp Ctrlq Ctrlr Ctrls Ctrlt
Ctrlu Ctrlv Ctrlw
Ctrlx Ctrly Ctrlz DefaultBaseline DefaultFontFamilySize
DefaultLineGrid DefaultMarginTabsArray
DefaultMask DefaultRule DefaultSpace DefaultTab DefaultTabsArray ESC
EndOfRun Enter Italic
Justified LeftFlush LeftMarginTab RightFlush RightMarginTab Space
Tab TextSharedInformation'
package: 'Text-Core-Base'我们再次建议您避免使用池变量和池词典。
10.25 抽象方法和抽象类
抽象类是为了被子类化而不是被实例化而存在的类。抽象类通常是不完整的,因为它没有定义它使用的所有方法。“占位符”方法,即其他方法假定是(重新)定义的那些方法称为抽象方法。
Pharo没有专门的语法来指定哪个方法或类是抽象的。相反,按照惯例,抽象方法的主体由表达式self subclassResponsibility组成。这表明子类有责任定义方法的具体版本。self subclassResponsibility方法始终应该被重写,永远不应该被执行。如果您忘记了重写,并且它被执行了,将会引发异常。
类似地,如果一个类的方法之一是抽象的,则它也被认为是抽象的。实际上,没有什么可以阻止您创建抽象类的实例;在调用抽象方法之前,一切都会正常工作。
10.26 示例:抽象类Magnitude
Magnitude是一个抽象类,它帮助我们定义可以相互比较的对象。Magnitude的子类应该实现方法<、=和hash。使用这些消息,Magnitude定义了其他的方法,如>、>=、<=、max:、min:,Between:and:,以及其他用于比较对象的方法。这样的方法由子类继承。方法Magnitude>><是抽象的,其定义如以下脚本所示。
清单10-39 Magnitude>> <
Magnitude >> < aMagnitude
"Answer whether the receiver is less than the argument."
^self subclassResponsibility相比之下,>=方法是具体的,它是基于<定义的。
清单10-40 Magnitude>> >=
Magnitude >> >= aMagnitude
"Answer whether the receiver is greater than or equal to the
argument."
^(self < aMagnitude) not其他比较方法也是如此(它们都是根据抽象方法<定义的)。
Character是Magnitude的子类;它用自己的版本(请参见下面的方法定义)覆盖掉<方法(如果您还记得的话,它通过使用self subclassResponsibility标记为Magnitude的抽象方法)。脚本10-41)。Character还显式定义了方法=和hash;它从Magnitude继承了>=、<=、~=等方法。
清单10-41 Character>> <=
Character >> < aCharacter
"Answer true if the receiver's value < aCharacter's value."
^self asciiValue < aCharacter asciiValue
10.27 本章小结
Pharo的对象模型既简单又统一。一切都是对象,几乎所有的事情都是通过发送消息来实现的。
一切都是对象。像整数一样的原始实体是对象,类也是第一类对象。
每一个对象都是某个类的实例。类通过私有实例变量定义其实例的结构,并通过公共方法定义其实例的行为。每个类都是其元类的唯一实例。类变量是由类和类的所有实例共享的私有变量。类不能直接访问其实例的实例变量,实例也不能访问其类的实例变量。如果需要,必须定义访问器。
每个类都有一个超类。单一继承层次结构的根是
ProtoObject。但是,您定义的类通常应该从Object或其子类继承。没有定义抽象类的语法。抽象类只是一个带有抽象方法的类(其实现由表达式self subclassResponsibility组成)。尽管Pharo只支持单一继承,但通过将方法的实现打包为特征,可以很容易地共享它们。一切都是通过发送信息来实现的。我们不调用方法,我们只发送消息。然后,接收者选择自己的方法来对消息作出响应。
方法查找遵循继承链;
self发送是动态的,从接收者的类中开始方法查找,而super发送是在编写super发送的类的超类中开始方法查找。从这个角度来看,super发送比self发送更静态。共有三种变量。全局变量在系统中的任何位置都可以访问。类变量在类、其子类及其实例之间共享。池变量在选定的一组类之间共享。您应该尽可能避免共享变量。